









Pour comprendre pourquoi un développeur web et beaucoup d’autres métiers de l’informatique utilisent Git et plus généralement le versioning, il faut revenir à une problématique fondamentale.
Le code source
Les applications, les logiciels, les sites web ont tous pour point commun d’être composés de code, qui lui-même est composé de texte, dans différentes extensions de fichiers correspondants au langage de programmation dans lequel ils sont écrits (.js, .php, .css, .py…). Ce texte n’est pas le même que sur un document Word : chaque caractère est important et peut faire la différence entre erreur fatale et fonctionnement. Un running gag connu est celui du point virgule mal placé ou oublié.

La somme de tous les fichiers qui composent un site ou un programme est appelée code source.
Ces fichiers ne sont pas très lourds en terme de poids. Une bonne pratique veut aussi de les garder courts et de pratiquer le code splitting (fractionner les différents scripts) pour améliorer la lisibilité et les performances.
Seulement des fichiers plus volumineux et non textuels peuvent se rajouter : images, polices d’écriture, pictogrammes… En bref, un code source peut vite devenir encombrant.
Un exemple parlant : la base de WordPress, téléchargeable sur wordpress.org, fait environ 70 Mo. Sachant qu’il s’agit d’une base sur laquelle beaucoup d’extensions vont venir se greffer ! Un site complet peut rapidement peser 200 Mo, 500 Mo, voire plus d’1 Go avec les thèmes et les images.
Maintenant, imaginez que tout ce code source soit déplacé de la même manière qu’un document Word ou un fichier Photoshop, par exemple via un service de stockage cloud comme Dropbox. Imaginez de nouveau ce transfert à chaque modification : si la modification en question concerne plusieurs centaines de fichiers, il faudrait garder une trace de tous les fichiers modifiés pour les remplacer, ou bien transférer tout le projet entièrement à chaque fois ? Heureusement, les développeurs n’ont plus à se poser ces questions. Git permet de se détacher totalement de ce problème avec une vitesse de transfert record, le tout documenté et avec un historique grâce à quelques commandes.
Travailler en collaboration
Si ce code a vocation à être déplacé, c’est aussi parce qu’il est conçu en collaboration avec plusieurs personnes. Ensuite, il sera lui-même diffusé en ligne sur un serveur.
Selon la taille du projet, plusieurs développeurs vont participer et écrire du code, parfois même en simultané. Il faudra donc ensuite fusionner (merge) les modifications de tous les côtés, sans se soucier d’un ordre quelconque (du moment que les fonctionnalités n’ont pas de rapport entre elles). Ce système est asynchrone puisque plusieurs personnes peuvent travailler sur un même projet simultanément, mais sans répercussion des modifications de l’autre. Une fois terminé, il faudra faire une fusion pour regrouper le code.
C’est encore plus vrai dans la communauté open source sur un projet public où tout le monde peut proposer un changement.
Les logiciels de versioning à la rescousse
S’il existe d’autres systèmes de gestion de versions, notamment SVN ou encore Mercurial, cet article ne parlera que de Git qui est utilisé dans 90% des cas.Il a été créé par Linus Torvalds, qui est aussi à l’origine du noyau de Linux.
Le terme version est important, parce que grâce à ce système, plusieurs versions du code source vont co-exister, et ceci à travers des branches. Il fait également référence à la gestion sémantique de versions qui représente un numéro incrémental selon la convention majeur.mineur.correctif, par exemple 1.0.0, 1.2.1… utilisée à peu près partout en termes de sites, logiciels, applications. Dans le cas de Git, il est possible de documenter ces numéros à l’aide de tags.
GitHub, Bitbucket, Gitlab…
Ce sont des logiciels de gestion de dépôts pour Git. Ils sont tous à leur façon un moyen de représenter le versioning via une interface.
C’est utile pour visualiser toutes les informations qui transitent de manière plus accessible, mais aussi pour le partager au grand public et même directement gérer le code depuis celui-ci.
Une fois qu’un projet est relié à un de ces services, le dépôt est dit remote et non plus local. Il n’est donc plus centralisé sur une machine mais en ligne et pourra être partagé plus facilement.
De nombreuses autres fonctionnalités en font des outils indispensables : pull requests open-source, connexions SSH, déploiements, automations…
A noter que si GitHub et Gitlab sont gratuits, ce n’est pas le cas de Bitbucket qui est plutôt utilisé par les entreprises de manière privée.
Le jargon
Dans le versioning, chaque itération du code correspond à un commit. Il s’agit d’une action déterminée par un certain nombre de changements parmi les fichiers, qui est identifiée par une heure et son créateur ainsi qu’un message libre. Cette suite d’actions correspond à l’évolution du projet. Certains commits peuvent être plus volumineux que d’autres, ou ayant pour rôle de fusionner deux branches entre elles. Ils seront toujours classés par ordre antéchronologique.
Quelques commandes sont indispensables et sont à connaître sur le bout des doigts pour une utilisation quotidienne. Pour rappel, nous expliquions sur un autre article dédié à Linux la composition d’une commande :
git pull: récupérer sur un projet les derniers commits afin d’avoir un dépôt local à jourgit status: vérifier l’état actuel du versioning, montrer si des fichiers ont actuellement des modificationsgit branch: voir la liste des branchesgit checkout -b <new-branch>: créer une nouvelle branchegit add .: ajouter tous les fichiers modifiés au commit futurgit commit -m "Message": créer un nouveau commit avec les changements ajoutés et un message entre guillemetsgit push: envoyer le commit dans le dépôt distantgit log: liste les derniers commits
Les exceptions et .gitignore
Revenons à notre problématique des fichiers volumineux comme les images. En fait, ces images n’ont pas vocation à être versionnées, notamment à cause de leurs poids et leur nombre qui viendraient polluer le dépôt, mais aussi de leur caractère illisible.
Les images ne sont pas seules, d’autres fichiers ne doivent tout simplement pas faire partie du versioning. Ils sont aussi appelés non suivis car les fichiers sont tracked dans le cas contraire. Pour cela, il faut indiquer à Git de les ignorer, ils ne seront pas pris en compte et il faudra les ajouter manuellement par exemple via FTP ou dans le script déploiement.
C’est aussi le cas de tous les fichiers comportant des informations sensibles : clés d’environnements, informations de connexion à la base de données, logs… Mais aussi des nombreux fichiers de librairies et de dépendances : le dossier /vendor/ de composer ou encore /node_modules/ de npm.
Pour comprendre ce qui a sa place ou non sur un dépôt, il faut se demander :
– Est-ce que le fichier a une modification visible dans le code source ? Ce n’est pas le cas des images.
– Est-ce que le fichier a vocation à être modifié par l’auteur du dépôt ? Ce n’est pas le cas des librairies / dépendances.
– Est-ce que le fichier peut être visible à tous dans le cas d’un dépôt public ? Ce n’est pas le cas des clés d’environnements ni des logs.
Pour les ignorer, il faut lister selon des expressions régulières toutes les extensions de fichier ou l’emplacement des dossiers qui sont concernés et les ajouter, un par ligne, dans un nouveau fichier appelé .gitignore. Exemple :
*.log
/.htaccess
/license.txt
/sitemap.xml
*.DS_Store
/uploads
.envGérer ses environnements
Les commits peuvent être encore plus puissants s’ils sont effectuées sur des branches, qui instaurent une logique de co-existence des versions. Une branche est une copie d’une version à un instant donné, sur laquelle une fonctionnalité va être développée sans interférer avec la version de départ.
Comprendre les branches

Par exemple sur ce schéma, les points en blanc représentent la branche principale, toujours appelée master ou main. Il est de convention que cette branche représente l’état stable du projet, tel qu’il est actuellement en production, c’est-à-dire en ligne. Les points en orange peuvent représenter une deuxième branche créée pour développer une fonctionnalité qui a ensuite été fusionnée à la branche principale, et qui se trouve donc aussi en ligne. Enfin, les points en bleu représentent une branche en cours de développement.
Ce schéma reste relativement simple dans le sens où il n’y a qu’un seul environnement de production. Mais souvent, un deuxième environnement existe dans un état plus avancé que la production : l’environnement de pré-production ou staging.
Cet environnement a parfois une existence en ligne, par exemple via un sous-domaine : staging.mon-site.fr ou avec un Top Level Domain réservé tel que mon-site.staging ou encore mon-site.dev. Il a pour intérêt de tester une fonctionnalité avant de la déployer en production.
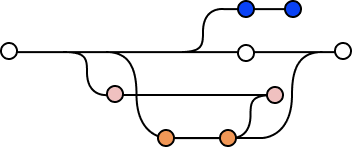
Le schéma se complexifie : si les branches démarrent toujours de master, le processus de fusion diffère : la nouvelle branche sera d’abord fusionnée sur develop puis sur master si tous les tests sont concluants. Mis à part lors de la création de la branche develop, les branches develop et master n’ont pas à communiquer, seules les fonctionnalités viennent s’ajouter une à une ce qui permet de maîtriser finement les versions.
Par exemple pour l’ajout d’une fonctionnalité sur la branche suivante : feature/rgpd qui aurait pour but de rendre un site compatible en termes de RGPD, voici les commandes à effectuer :
git checkout master: se placer sur la branche principalegit pull: récupérer les dernières modifications pour éviter les conflitsgit checkout -b feature/rgpd: création de la branche à partir de la version de productiongit add .: ajout des fichiers modifiésgit commit -m "Conformité RGPD": ajout d’un commit avec un messagegit push (-u origin feature/rgpd): pousser la branche sur le dépôt. Une fois que la branche existe en remote, la partie entre parenthèse n’est plus nécessaire.git checkout develop: se placer sur la branche de staginggit pullgit merge feature/rgpd: fusionner la nouvelle branche sur le staginggit pushgit checkout master: une fois que tout est validé, se placer sur la branche de productiongit pullgit merge feature/rgpd: fusionner la nouvelle branche en productiongit push
Sur le serveur de staging et de production, un simple git pull permet de récupérer le code source à jour.
Attention aux conflits de merge
Parfois un même fichier est modifié depuis deux branches différentes. Dans ce cas, Git n’est plus capable de fusionner, il va alors falloir intervenir pour terminer le merge.
Pour chaque fichier, il faut décider quelle modification conserver entre la modification actuelle (current) ou la modification la plus récente (incoming). Encore une fois tout peut se faire à l’aide de commandes :
- git checkout –ours . : régler tous les conflits en récupérant le code current
- git checkout –theirs . : de même mais pour le code incoming
Ensuite, les fichiers doivent être commités :
git add .
git commit -m "Fix merge conflicts"
git pushGarder le contrôle sur un projet
Un code sous système de versions aura l’avantage de ne laisser passer aucune modification inaperçue. Une fois sur le serveur par exemple, un simple git status rendra compte des modifications apportées en dehors du versioning. Et en seulement deux commandes, l’intégralité du code superflu pourra être nettoyé :
git clean -fd
git checkout -- .Dans le cas d’un site avec WordPress, il est facile de surveiller des mises à jours qui auraient été effectuées depuis le back-office, ou encore des ajouts ou suppression de plugins : des informations cruciales quand il s’agit de débugger un site.
Sur le dépôt, il est possible de remonter tout l’historique d’un site et donc de connaître l’ajout ou le retrait d’une fonctionnalité
En surface, Git est indispensable dans le développement d’un projet informatique. Mais de nombreux autres concepts plus complexes peuvent permettre de faire face à des situations compliquées. Pour cela, ne pas hésiter à se référer à la documentation complète de Git.










